
Bases de Données et Big Data
Les bases de données sont essentielles pour stocker, gérer et organiser les informations de manière efficace et sécurisée. Elles permettent d’optimiser les performances des applications et facilitent la prise de décision en entreprise. J’ai choisi ce thème car il est au cœur du développement logiciel et indispensable pour concevoir des systèmes performants. La maîtrise des bases de données, qu’elles soient SQL ou NoSQL, est un atout majeur pour un développeur. Elle ouvre de nombreuses opportunités dans les domaines du développement, de l’analyse de données et de la cybersécurité.

Oracle a récemment lancé GenDev, une nouvelle infrastructure de données centrée sur l'IA, conçue pour transformer la manière dont les entreprises gèrent et utilisent leurs données. Cette solution permet d’intégrer des bases de données relationnelles avec des formats de données flexibles tels que le JSON, facilitant ainsi la gestion de données structurées et non structurées. GenDev vise à rendre les applications plus intelligentes en intégrant des capacités d’IA directement dans l'infrastructure des bases de données. Cela permet aux entreprises de créer des applications plus performantes et résilientes, tout en optimisant la gestion des données dans des environnements cloud. Cette avancée est particulièrement utile pour les développeurs, car elle simplifie l'utilisation de l'IA dans les processus métiers, offrant ainsi une approche plus fluide et évolutive pour répondre aux besoins de données complexes.
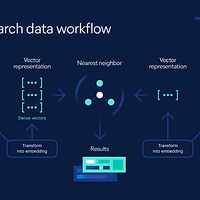
MariaDB Enterprise Platform 2025 intègre désormais la recherche vectorielle native, une fonctionnalité clé pour le traitement des données non structurées. Cette avancée permet aux utilisateurs d’exploiter des algorithmes de recherche de similarité directement au sein de la base de données, sans dépendre de solutions tierces comme Elasticsearch ou Faiss. L’objectif de MariaDB est de se positionner comme une alternative robuste aux bases de données spécialisées en recherche vectorielle, tout en conservant la flexibilité et la compatibilité avec les systèmes relationnels traditionnels. La recherche vectorielle repose sur la conversion d’objets complexes (textes, images, sons, etc.) en vecteurs numériques multidimensionnels. Ces vecteurs permettent d’évaluer la proximité entre des données en calculant leur similarité dans un espace mathématique. Par exemple, dans le cas d’une recherche d’images, un moteur basé sur la recherche vectorielle peut retrouver des images visuellement similaires à une image donnée en mesurant la distance entre leurs vecteurs respectifs. En intégrant cette technologie de manière native, MariaDB évite aux utilisateurs d’avoir à exporter et traiter ces données dans des outils externes, optimisant ainsi les performances et la gestion des ressources. Conclusion: L’ajout de la recherche vectorielle native à MariaDB marque une avancée significative pour les entreprises exploitant des volumes massifs de données non structurées, notamment dans les domaines de l’intelligence artificielle, de l’analyse sémantique et de la reconnaissance d’images. Cette innovation permet d’accélérer les recherches complexes tout en réduisant la dépendance à des infrastructures additionnelles, simplifiant ainsi l’architecture des applications et améliorant leur efficacité.

Le stockage de données à l’échelle moléculaire est en train de devenir une réponse sérieuse à l’explosion des volumes d’informations numériques. Un article du Monde publié en septembre 2024 met en avant les recherches de Jean-François Lutz sur les polymères informationnels, capables de coder des données numériques via l’organisation de molécules synthétiques. Ces nouveaux supports, beaucoup plus denses et stables que les disques durs traditionnels, pourraient révolutionner les futurs centres de données en réduisant l’espace nécessaire et la consommation énergétique. En parallèle, des entreprises comme la start-up française Biomemory se distinguent par des innovations concrètes dans le stockage sur ADN. Biomemory utilise des plasmides, des fragments circulaires d'ADN, pour inscrire et conserver des données de manière extrêmement durable. Grâce à des procédés biologiques, l’information peut être facilement dupliquée et protégée sur de très longues périodes, sans besoin d’énergie continue. Ce modèle présente aussi des avantages écologiques majeurs, en diminuant l’empreinte carbone du stockage. Soutenus par des programmes comme France 2030, ces projets montrent que le stockage moléculaire pourrait devenir une solution incontournable pour répondre aux défis du Big Data. Ainsi, cette avancée technologique ouvre la voie à de nouvelles formes d’archivage, plus compactes, sécurisées et respectueuses de l’environnement.

Neo4j Infinigraph : performance et analyse sur un seul système
Neo4j est un leader mondial des bases de données orientées graphes, spécialisées dans l’analyse des relations complexes entre données (fraude, recommandations, réseaux, etc.).
Avec Infinigraph, Neo4j introduit une véritable avancée : contrairement aux bases de données traditionnelles, qui séparent généralement les traitements transactionnels (OLTP, ex. : enregistrer une commande en ligne) des traitements analytiques (OLAP, ex. : analyser toutes les commandes du mois), Infinigraph réunit ces deux mondes dans une seule plateforme. Là où une base classique oblige à copier et déplacer les données vers un système dédié à l’analyse, Infinigraph permet de gérer à la fois les transactions en temps réel et les analyses massives directement sur les graphes, tout en conservant performance et fiabilité (ACID).
En pratique, cette innovation pourrait permettre aux entreprises de détecter instantanément des fraudes bancaires, d’adapter en temps réel les recommandations d’un site e-commerce, ou encore d’optimiser des réseaux logistiques à la volée, sans architectures lourdes ni délais liés aux transferts de données.


Les bases de données Serverless : une révolution dans la gestion des données modernes
Les bases de données serverless représentent l’une des avancées les plus marquantes de 2024–2025 dans le domaine du stockage et de la gestion des données. Elles proposent un modèle où l'infrastructure devient totalement invisible pour le développeur : plus besoin de gérer des serveurs, de dimensionner les ressources ou d’assurer la maintenance, tout est automatisé. Leur grand atout réside dans la scalabilité automatique, capable d’augmenter ou réduire la puissance de calcul en fonction de la charge en temps réel, ce qui est particulièrement utile pour les applications modernes, les environnements cloud, les microservices et les API à fort trafic variable. En 2025, les progrès majeurs concernent la réduction drastique du cold start à moins de 50 millisecondes, une connectivité persistante ultra-rapide, et des systèmes multi-zones capables d’assurer une haute disponibilité sans configuration manuelle. Des plateformes comme Neon (PostgreSQL serverless), PlanetScale (MySQL serverless) et Firebolt ont introduit des architectures innovantes basées sur la séparation du stockage et du compute, permettant une facturation ultra-précise « à l’usage » et une mise à l’échelle presque instantanée. De plus, l’acquisition de Neon par Databricks en 2025 renforce encore l’importance des bases serverless dans l’avenir de l’IA, des infrastructures cloud-natifs et des systèmes distribués modernes. En résumé, les bases de données serverless transforment profondément la façon de concevoir des applications, en offrant performance, économies et flexibilité tout en supprimant les contraintes opérationnelles traditionnelles.